들어가며
2022년 1학기에 수강한 Gaya 교수님의 '딥러닝 1: 이미지 처리' 수업의 기말 프로젝트 일환으로
CvT: Introducing Convolutions to Vision Transformers라는
논문의 발표와 코드 작성(기존의 코드를 목적에 맞게 reproducing) 프로젝트를 진행하였다.
인공지능 공부를 시작한 지 얼마 되지 않았기에 인공지능 분야의 논문을 제대로 읽어보는 것은
겨우 두 번째였고(첫 번째도 Gaya 교수님 중간 프로젝트의 일환으로 읽어 본 bias paper 였음...),
Vision Transformers를 적용한 논문이었기에 딥러닝 초짜인 나에게 진입장벽이 굉장히 높았었다.
CvT(Convolutions to Vision Transformers)를 이해하기 위해 Vision Transformers를 공부하고,
Vision Transformers를 이해하기 위해 Transformers(Attention Is All You Need)를 공부하고,
Transformers를 이해하기 위해 Seq2Seq, LSTM, RNN을 공부하고...
학기 중이라 다른 과목의 공부와 병행해야 했기에 쉽지 않은 프로젝트였지만
최대한 위에서 언급한 논문들의 핵심 개념들만 이해한 채 CvT 프로젝트를 진행했고,
우려와 달리 꽤나 만족스러운 결과를 얻었을 수 있었다.
(위에서 언급한 모든 논문들을 읽으며 공부하기엔 시간이 없었기에, 유튜브와 블로그에 정리된 자료들을
찾아보며 공부했었다. 공부할 때 참고한 자료와 사이트들을 모아놓은 google docs가 사라졌기에
공유 못 함......)
자료 및 설명
프로젝트는 나를 포함하여 두 명이서 진행했고, 발표 자료와 코드는 다음과 같다.
(PPT: 각 슬라이드마다 발표 대본 확인 가능, Code: markdown, comments에서 설명 확인 가능)
https://github.com/sbY99/ReproduceCvT
GitHub - sbY99/ReproduceCvT
Contribute to sbY99/ReproduceCvT development by creating an account on GitHub.
github.com
참고로 코드는 내가 진행한 파트에 대한 코드만 첨부하였으며, 각각의 폴더에 포함된 내용을 요약하자면 다음과 같다.
1. ImageNetTask
논문에서 제시한 CvT 모델의 성능을 평가하기 위한 코드.
논문에서는 ImageNet, ImageNet21K 등 매우 큰 Dataset을 활용하여 성능을 평가하였으나
내가 코드를 작성한 코랩 Pro 환경에서는 해당 데이터를 처리할 수 없었기 때문에,
Pre-trained on ImageNet model을 불러와서 ImageNet validation set에 대한 성능 평가를 진행했다.
모델의 성능 비교를 위해 CvT 뿐만 아니라 ResNet_50, ViT-B-16 모델에 대한 성능 평가도 진행하였으며
모델의 정확도와 성능 평가에 소요된 시간, 파라미터의 개수를 모델의 성능 평가 요소로 활용했다.
2. FineTuning
CvT 모델이 Fine Tuning Tasks에서도 좋은 성능을 보인다는 것을 증명하는 실험을 위한 코드.
논문에서 CvT와 함께 비교하고 있는 모델인 BiT, ViT에 대해서도 Fine Tuning Tasks를 수행하였으며,
Pre-trained on ImageNet22 k model을 불러와 CIFAR-10 dataset에 대한 성능 평가를 진행했다.
ImageNet22k와 CIFAR-10 dataset의 특징에 따라 full layers에 대한 fine tuning을 진행하는
Stragety를 설정하였으며, 정확도와 학습 시간, 파라미터의 개수를 모델의 성능을 비교하는 지표로 활용했다.
3. AblationPosEmb
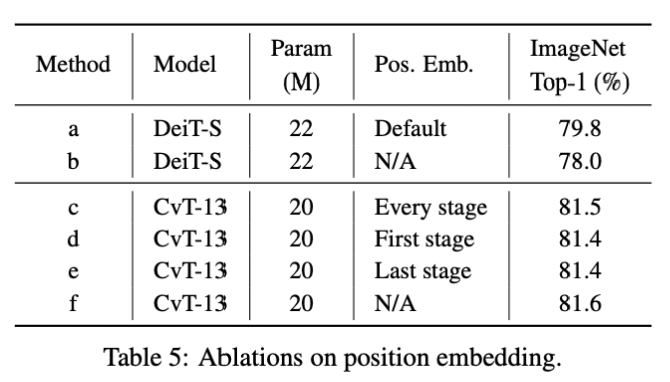
기존의 존재하던 Position Embedding을 효과적으로 제거했음을 입증하는 실험을 위한 코드.
Vision Transformers를 활용한 모델인 DeiT-S의 경우에는
Position Embedding을 제거했을 때 유의미한 성능 하락이 발생하지만,
CvT의 경우 Position Embedding을 제거했을 때와 Position Embedding을 유지할 때를 비교한 결과
유의미한 성능 차이를 보이지 않았음을 보임으로써 주장을 입증하였다.
모델을 새로 정의한 채 학습해야 했기에 Imagenette2라는 custom dataset을 활용하였으며,
해당 dataset을 활용하기 위한 전처리 기법들을 코드의 전반부에서 확인할 수 있다.
각 모델의 Position Embedding 활성화 여부를 조절하기 위해
각 논문의 저자들이 공유한 코드의 일부를 코랩 환경에 불러와서 수정하였다.
코랩 환경에서 코드를 실행하기 위해 파일 내부에서 수정한 내용도 있기 때문에(module import 관련 부분)
코드에서 text로 설명하고 있는 guide를 잘 읽어보길 추천드린다.
CvT 모델은 Vision Transformers의 구조를 활용한 모델로서,
논문의 제목에서도 확인할 수 있듯이 Vision Transformers에 Convolution을 적용한 구조이다.
CvT의 차별되는 또 다른 특징으로는 Vision Transformers의 큰 특징인 Position Embedding을
제거했다는 것이다.
Position Embedding을 제거함으로써 higher resolution vision tasks에 대한 design을 간략화할 수 있다.
논문 설명
1. Abstract
Convolutional vision Transforemr(CvT)는 Vision Transformer(ViT)에 convolutions를 적용함으로써
peformance와 efficiency 측면에서의 향상을 이룬 모델이다.
CvT는 ViT와 비교했을 때 두 가지 주요한 차이점이 존재한다.
1. Convolutional token embedding
- 2D tokem map에 overlapping convolutional with stride 연산을 수행
- Capture local information + Spatial downsampling
2. Convolutional projection
- ViT의 linear projection을 depth-wise convolutional 연산으로 대체
- Capture local spatial context + Reduce semantic ambiguity in the attention mechanism
+ Permits management of computational complexity with minimal degradation of performance
위의 두 가지 특징은 ViT architecture가 가지는 transformers의 장점(dynamic attention,
global context, generalization)을 유지하면서 Convolutional Neural Networks(CNNs)의 특징을 부여해준다.
즉, CvT는 ViT를 활용한 모델로, transformers의 장점을 가짐과 동시에
local structure에 대한 정보 습득력이 뛰어난 CNN의 장점을 동시에 갖는 모델이라 할 수 있다.
CvT는 더 적은 수의 파라미터와 계산량을 가지면서도 다른 모델들(ViT, ResNets, DeiT, 등등)에 비해
뛰어난 성능을 보여줬으며, Fine tuning tasks에서도 좋은 성능을 보였다.
뿐만 아니라 ViT의 중요한 요소라 할 수 있는 positional encoding을 효과적으로 제거함으로써
높은 해상도를 가지는 vision tasks에 대한 design을 간략화했다.
2. Methods
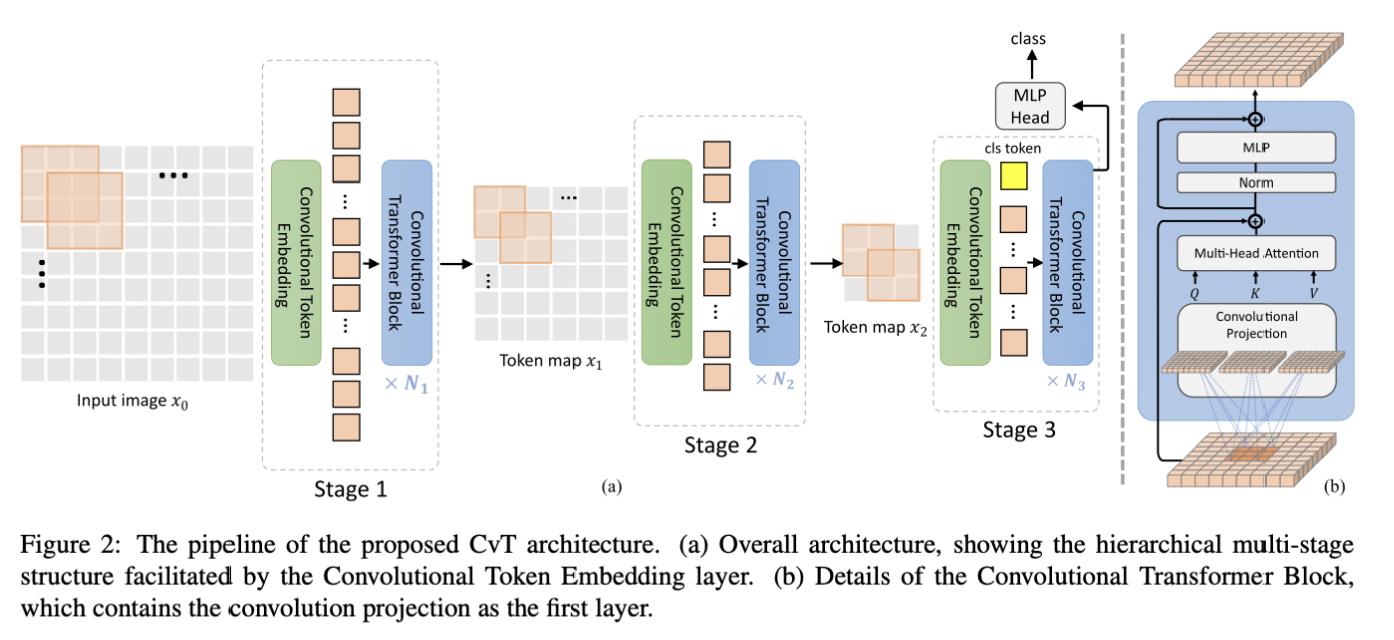
CvT의 구조는 위와 같다.
CvT는 크게 3개의 stage로 구성되며, 각 stage는 2개의 parts로 구분된다.
첫 번째 part에서는 input image, 혹은 2D reshaped toekm maps이
Convolutional Token Embedding layer를 통과하는데,
이름에서도 알 수 있듯이 convolutional with overlapping 연산을 수행하게 된다.
그 결과로써 2D spatil grid가 생성되며, 이후 각 tokes에 대해 normalization이 적용된다.
이러한 과정은 tokens의 개수를 줄이면서 tokens의 width를 증가시키는데,
이는 CNN에서 볼 수 있는 spatial donwsampling과 richness of representation의 증가를 의미한다.
간략하게 수식적으로 표현하자면 다음과 같다.
Stage i-1의 결과로서 Stage i에 주어진 input image가
이는 stride가 존재하는 convolutional 연산을 수행하고 2차원으로 flatten 됨에 따라
첫 번째 part를 통해 출력된 결과물은 두 번째 part에 입력된다.
두 번째 part는 위 그림에서 Convolutional Transformer Blocks에 해당하며,
이를 자세히 표현한 것이 그림에 우측에 있는 (b)이다.
Convolutional Transformer Blocks에서는 ViT의 Linear projection 대신
Convolutional projection을 수행한다.
즉, 입력된 값이 fully connected layer를 거치는 것이 아닌,
Depth-wise convolutional 연산을 통해 Q, K, V를 생성하게 된다.
Convolutional projection의 목표는 Q, K, V를 생성하는 과정에서
Local spatial context를 얻기 위함이며, K와 V 행렬의 under-sampling에 대한 효율성을 제공한다.
본 논문에서는 convolutional projection을 수행할 때 K와 V에 대해 stride를 2로 설정함으로써
성능의 소폭 하락을 감수하며 모델의 연산 속도를 높였다.

위는 ViT의 linear project과 convolutional projection의 과정을 도식화한 것이다.
(b)에서 확인할 수 있듯,
적절한 convolutional 연산이 가능한 형태로 reshape 된 후, convolutional 연산이 수행되어
query, key, value matrics를 생성한다.
(c)는 앞서 언급한 바와 같이 key와 value matrics를 생성할 때
stride를 2로 설정한 것이며, 논문에서는 이를 모델의 기본 설정으로 구성했다고 한다.
Summary & Further Explanation
Convolutional vision Transformer(CvT) introduces two core sections of the Vision Transformer(ViT) architecture.
First, the authors divided the Transformer into multiple stages that form a hierarchical structure of Transformer. The beginning of each stage consists of a Convolutional Token Embedding that performs an overlapping convolution operation with stride on a 2D-reshaped token map, followed by layer normalization. Given a two- dimensional input image from the previous stage, function f() that maps to a new token with a channel size
Second, Convolutional Transformer Blocks comprise the remainder of each stage. The Convolutional Transformer Blocks replaced the original linear projection with the Convolutional Projection. Given a
The prediction class is obtained using the cls token and multi-layer perceptron at the last stage, the same as ViT.
3. Experiments
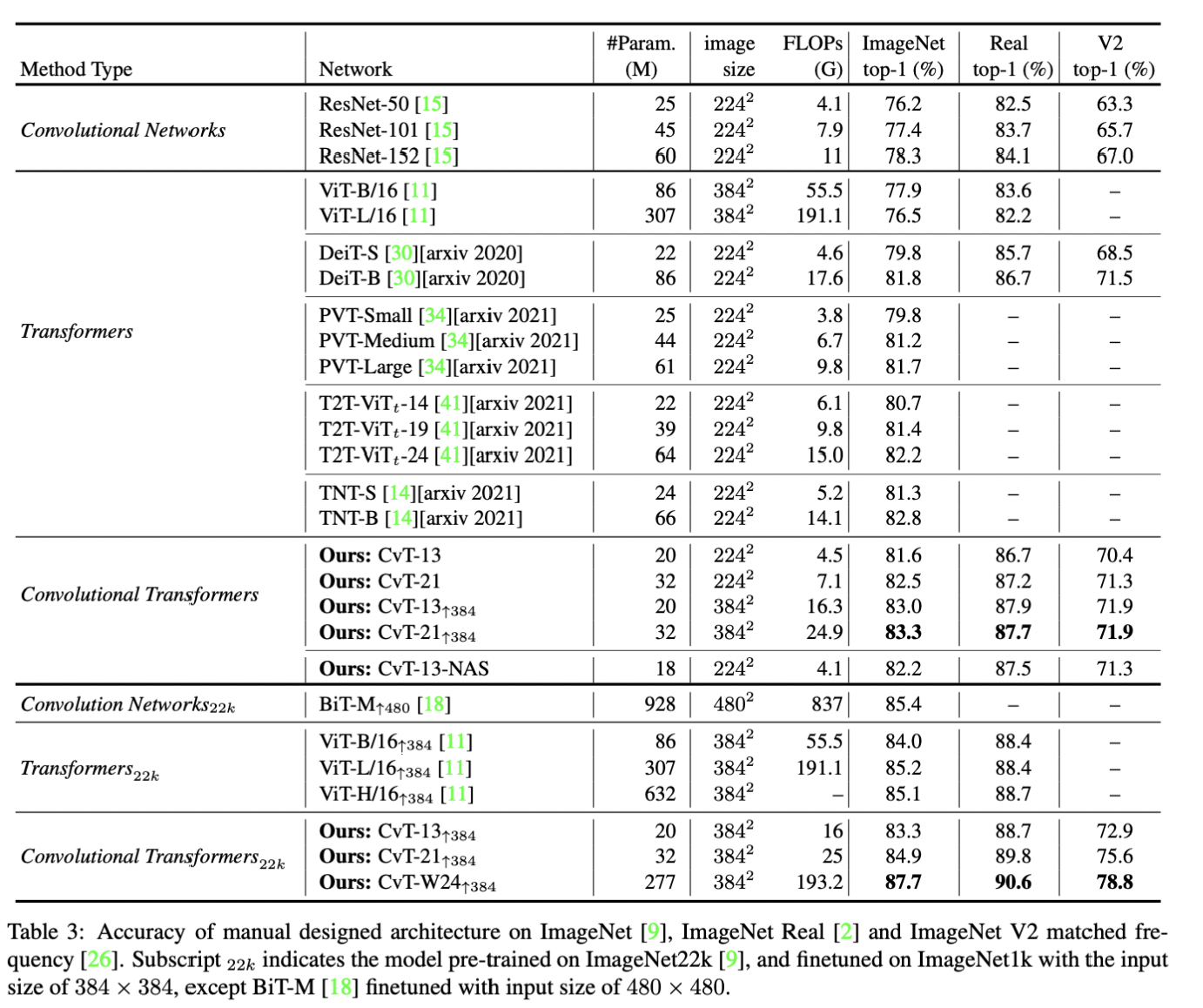
해당 논문에는 다른 모델들과의 성능 비교 실험들 뿐만 아니라,
ViT와 비교했을 때 중요한 변경 사항인 Position Embedding, Convolutional Token Embedding,
Convolutional Projection의 유무에 따른 성능을 평가 실험을 진행하였다.
저자들은 유무를 조절함으로써 해당 구조가 성능에 영향을 미치는 지를 판단하는 실험을
Ablation Study라 칭하고 있으며, 이를 통해 해당 논문에서 제안한 구조가 성공적임을 증명한다.



4. Conclusion
본 논문에서는 Transformer의 이점과 CNNs가 갖는 이점을 동시에 갖도록
Vision Transformer architecture에 convolutions을 적용하였다.
ViT 모델에 Convolutional token embedding과 Convolutional projection를 추가했으며,
다양한 최신 모델들과의 성능 비교와 Ablation Study를 통해 주장을 입증할 수 있었다.
CvT는 연산 효율성을 증대시킴과 동시에 최고의 성능을 달성했을 뿐만 아니라,
Position Embedding을 효과적으로 제거함으로써 다양한 입력 이미지의 해상도를 필요로 하는
wide range of vision tasks에 대한 적응력을 향상 시켰다.
References
댓글